£0.00

25 września 2021 r.
Komentarze są wyłączone na Czym jest sharding i dlaczego trudno go wprowadzić?
Dla platform blockchain wykonanie shardingu jest trudne. Ponieważ jest bardziej skomplikowany i trudny w użyciu. W tradycyjnej konfiguracji bazy danych jest to metoda skalowania większych baz danych.
Problemy ze skalowalnością i złożoność
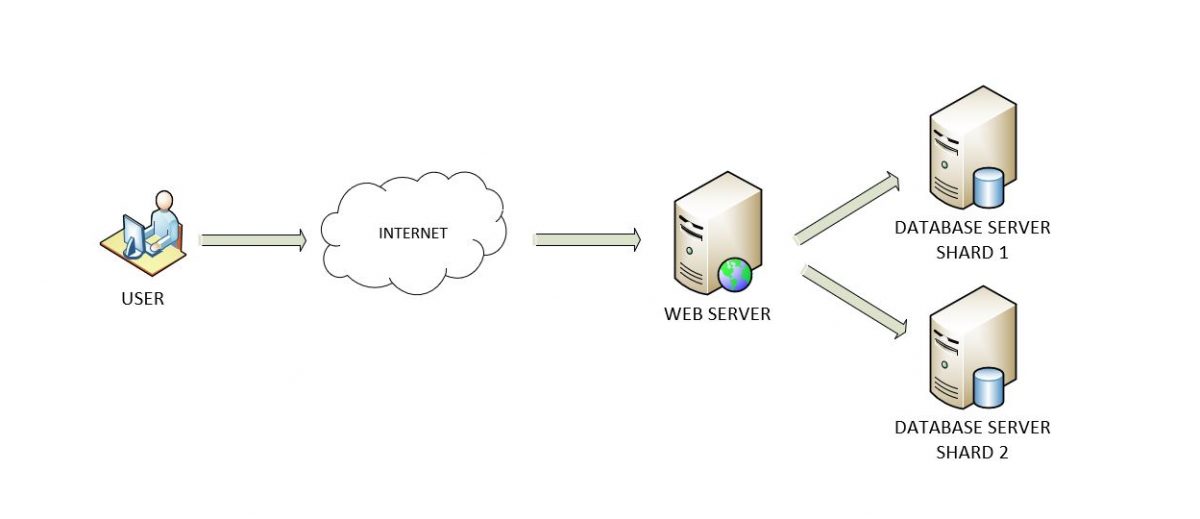
Skalowanie pomaga w tworzeniu zapytań, w związku z tym, pamiętając o technikach dostępu. Oprócz powyższej definicji, ogromne bazy danych są poziomo podzielony. Wiąże się to z wieloma mini bazy danych że  nie udostępniaj szczegółów. W rezultacie jego zapytania i skalowanie są teraz uproszczone. W związku z tym, nie ma potrzeby dodawania dodatkowych informacji.
nie udostępniaj szczegółów. W rezultacie jego zapytania i skalowanie są teraz uproszczone. W związku z tym, nie ma potrzeby dodawania dodatkowych informacji.
nie udostępniaj szczegółów. W rezultacie jego zapytania i skalowanie są teraz uproszczone. W związku z tym, nie ma potrzeby dodawania dodatkowych informacji.Czas potrzebny na wykonanie zapytań jest skorelowany z rozmiarem bazy danych. Rezultatem są problemy ze skalowalnością, ponieważ prowadzi to do złożoności zapytań do bazy danych. Dane są podzielone na wiele baz danych. Następnie sortowanie według rozmiaru bazy danych. W takim przypadku dyskretna baza danych zaczyna rosnąć. Ponownie, infrastruktura wymagana do utrzymania staje się nieco złożona.
Bazy danych przekazywane przez sharding
Jedna podstawowa baza danych wymaga ogromnej mocy. Dokładne koszty mają zastosowanie, aby zapewnić powielanie danych obecnych w systemie. Takie aspekty łączą się, aby stworzyć wyzwanie dotyczące skalowania w konfiguracji bazy danych.
Sharding ma na celu naprawienie takich problemów. Dzieje się tak poprzez podział danych i koszty infrastruktury. Jeśli rozmiar się zmniejsza, minimalne techniki przetwarzania i powielania pomagają w zwiększeniu wydajności. Bazy danych przekazywane przez fragmentowanie stają się proste do uruchamiania zapytań. Wynika to z ich mniejszych rozmiarów. Ponadto dostarczanie takich baz danych to tańsze usługi hostingowe. Skalowanie może być nieograniczone, gdy istnieje odpowiednie wykonanie zasad shardingu.
Czy łańcuchy bloków wymagają implementacji shardingu?
Sharding można łatwo przeprowadzić za pomocą konfiguracji bardziej dostępnych reguł. Tutaj główna partia zarządza wszystkimi  czerep. W związku z tym, możesz uzyskać prawidłowe dane powiązane z pozycją danych. Ale w łańcuchu blokowym główna strona nie może śledzić danych obecnych w łańcuchu blokowym. Rezultat jest taki – wiele problemów, zwłaszcza z danymi używanymi w shardingu.
czerep. W związku z tym, możesz uzyskać prawidłowe dane powiązane z pozycją danych. Ale w łańcuchu blokowym główna strona nie może śledzić danych obecnych w łańcuchu blokowym. Rezultat jest taki – wiele problemów, zwłaszcza z danymi używanymi w shardingu.
czerep. W związku z tym, możesz uzyskać prawidłowe dane powiązane z pozycją danych. Ale w łańcuchu blokowym główna strona nie może śledzić danych obecnych w łańcuchu blokowym. Rezultat jest taki – wiele problemów, zwłaszcza z danymi używanymi w shardingu.Dobrym przykładem jest Ethereum, które jest drugim po Bitcoinie. W dzisiejszym świecie jest to używany blockchain. Zastosowanie dotyczy rozproszonych aplikacji i tokenów. Problemy ze skalowalnością dotykają ether ze względu na przepustowość transakcji. Ma limit od 15 do 20 transakcji na sekundę. Ten limit nie jest wystarczający, aby utrzymać funkcjonalność łańcucha bloków. Głównym czynnikiem decydującym jest procedura PoW (Proof-of-Work). Decyduje o kolejności każdej transakcji, aby uniknąć problemów z siecią. Każdy komputer w sieci powinien mieć dostępne kopie łańcucha bloków. Poza tym powinni mieć również zsynchronizowane transakcje.
Podobnie jak tradycyjne bazy danych, komputery w łańcuchu są zwykle umieszczane w podzbiorach. Późniejsze rozdrabnianie odbywa się zgodnie z procedurami sortowania. Wykładnicze skalowanie węzłów ma miejsce, ponieważ każdy fragment przetwarza transakcje równoległe. Jest to lepsze w porównaniu z procesem synchronizacji takich transakcji.